본 프로젝트는 멀티캠퍼스 AI 국비지원 과정에서 진행한 3번째 프로젝트이며,
빅데이터, AI, IOT, 클라우드의 교육과정들이 마지막으로 진행하는 융복합 프로젝트 형식이다.
매주 토요일마다 멘토분들이 현재 진행상황에 따른 피드백을 해주시고 그것을 토대로 진행하였다.
□ 프로젝트 개요
본 프로젝트는 딥러닝(Object Detection)으로 노년층, 일반층과 남성, 여성을 판단하여 노년층일 경우 UI가 변하고 STT로 주문을 유도하는 서비스이다. 또한 측정된 Label이 노년층 여성이면 노년층 여성이 많이 주문한 메뉴를 추천하는 키오스크이다.
□ 프로젝트 기간
2022년 5월 20일 ~ 2022년 6월 28일 (5.5주)
팀원 : AI 5명, 빅데이터 2명, IOT 2명, 클라우드 2명
총 11명
□ 기술 스택
1. AI
Object Detection(YOLOv5)
Speech to Text(CNN)
2. AWS
EC2, Lambda, System Manager, EventBridge, S3
3. Goofys
EC2 - S3 간 Mount(Folder)
4. Ubuntu
Shell Script Programming
□ 내 역할
- IMAGE Annotation 2400장
- YOLOv5 학습 및 추론
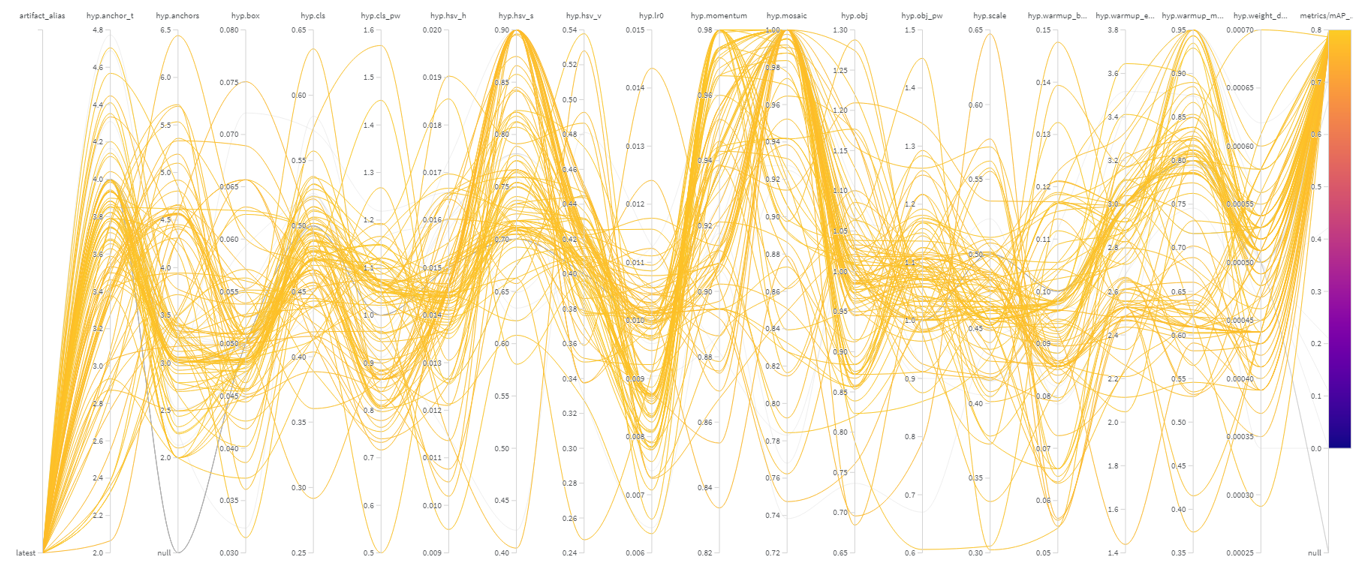
- 하이퍼파라미터 최적화
- Ensemble을 통한 YOLOv5 정확도 향상
- WeIghts and Biases(wandb) YOLOv5 모델 Monitoring
- Speech to Text(CNN)을 이용하여 구축
- AWS 서비스를 활용하여 MLops 구현
1. AutoLabeling 구축
2. Inference Pipeline 구축
3. AutoTrain Pipeline 구축
4. S3 버전관리 버킷을 통해 YOLOv5 Weight 버전관리
5. Linux Shell Script 작성□ 개발 환경
Inference(EC2) - inf1.xlarge
- Ubuntu 20.04 LTS
- Python 3.8
- torch 1.7.0
- torchvision 0.8.1
AutoTrain(EC2) - g4dn.xlarge
- Ubuntu 20.04 LTS
- Python 3.8
- torch 1.7.0
- torchvision 0.8.1
□ 개발 과정
내가 이번 프로젝트에서도 YOLOv5를 다시 사용한 이유는 MLops를 한번 구현해보고 싶었기 때문이다.
하지만 MLops는 내가 구현한 것 보다 더욱 기술적으로 고도화되어 있고 Docker, Kubernetes, Kubeflow, bentoML, MLflow 등 정말 많은 기술적인 툴들을 써야지 MLops라 부를 수 있겠지만, 나에겐 저런 툴들을 학습하면서 구현을 할 시간적인 여유가 없었다.

처음에는 AWS가 아닌 Linux Shell Script를 통해 모든것을 처리하려고 위에 보는 사진과 같이 구축하였었다.
하지만 멘토링에서 저런식이면 안하는게 낫다라는 피드백(쉘스크립트 하나라도 작동하지 않으면 모든게 무너짐)을 받고 AWS Service를 이용하여 구축을 시도하였다.
1. Inference Pipeline
Inference EC2 인스턴스는 inf1.xlarge를 사용하였고 추론 전용 인스턴스이다. 기존 GPU 인스턴스보다 저렴한 것이 장점

그래서 바꾼게 위에 보는 사진과 같이 AWS 서비스를 이용해서 Inference Pipeline을 구축하였다.
1. EventBridge로 키오스크가 작동하는 시간대 오전 8시 ~ 오후 8시에 자동으로 인스턴스 시작 / 중지(비용문제)
2. MQ로 S3에 IMAGE.jpg가 들어오면 Trigger가 발동하여 Lambda를 실행한다.
3. Lambda 함수에서 System Manager를 통해 EC2로 Run Command를 날려주는 코드를 통해 EC2 내의
Shell Script를 실행시킨다.
4. 추론 이후에 생성된 label.txt 파일은 S3 - EC2(Mount)내 폴더로 전송하여 데이터를 축적한다.
(추론 정확도 0.95 - 오차율 0%(AutoLabeling))
5. 추론된 label을 MQTT로 IOT에 전송
2. AutoTrain Pipeline

재학습의 주기가 60일인 이유는 추론 정확도 0.95이상으로 400장을 넣었을 때 총 15장만 나오게 되었다.
빅데이터 팀에서 키오스크를 이용하는 고객이 하루에 대략 500명이라고 전달 받았고, 하루에 약 20장의 데이터가 쌓이게 되고 최소 5000장을 생각했었지만 너무 재학습 기간이 길어지게 되었다. 60일도 상당히 길다고 생각했지만 1000장은 넘겨야 한다고 판단하여 60일 주기로 설정하게 되었다.
1. EventBridge를 통해 60일 주기로 인스턴스가 켜지고 약 2분정도의 딜레이 후에 Run Command를 날리도록 설정하였다.
2. Shell Script를 통해 학습이 시작되며 학습이 종료되면 Shell Script 마지막 단에 인스턴스를 종료하는 코드를 삽입 하였다.
3. 학습이 종료되기 전에 S3 버전관리 버킷으로 학습된 Weight 파일이 전송된다.
3. Object Detection(YOLOv5)
키오스크 이용하는 고객이 어떤 연령과 성별인지 구별하기 위한 방법으로 사용하였다.
Train image : 1900장
validation image : 500장
Label : 노인 남성, 노인 여성, 일반 남성, 일반 여성
학습 데이터는 위와 같으며 label은 총 4개로 구성
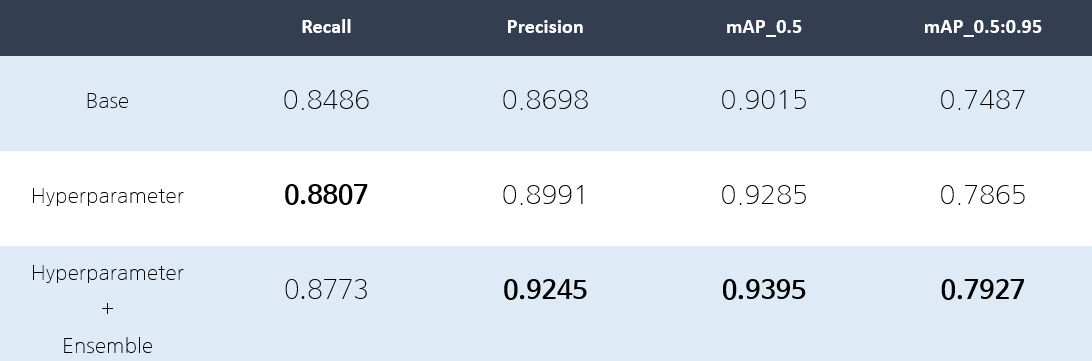
mAP_0.5 : 0.95의 정확도를 올리기 위해 하이퍼파라미터를 최적화를 진행하였고 다른 모델과의 앙상블을 통해 0.7927이라는 정확도까지 올렸지만 0.85까지가 목표였지만 달성하지 못하였다.
4. Speech to Text(CNN)
키오스크에서 노인으로 판별시 음성서비스 도움을 주도록하기 위해 STT를 사용하게 되었다.
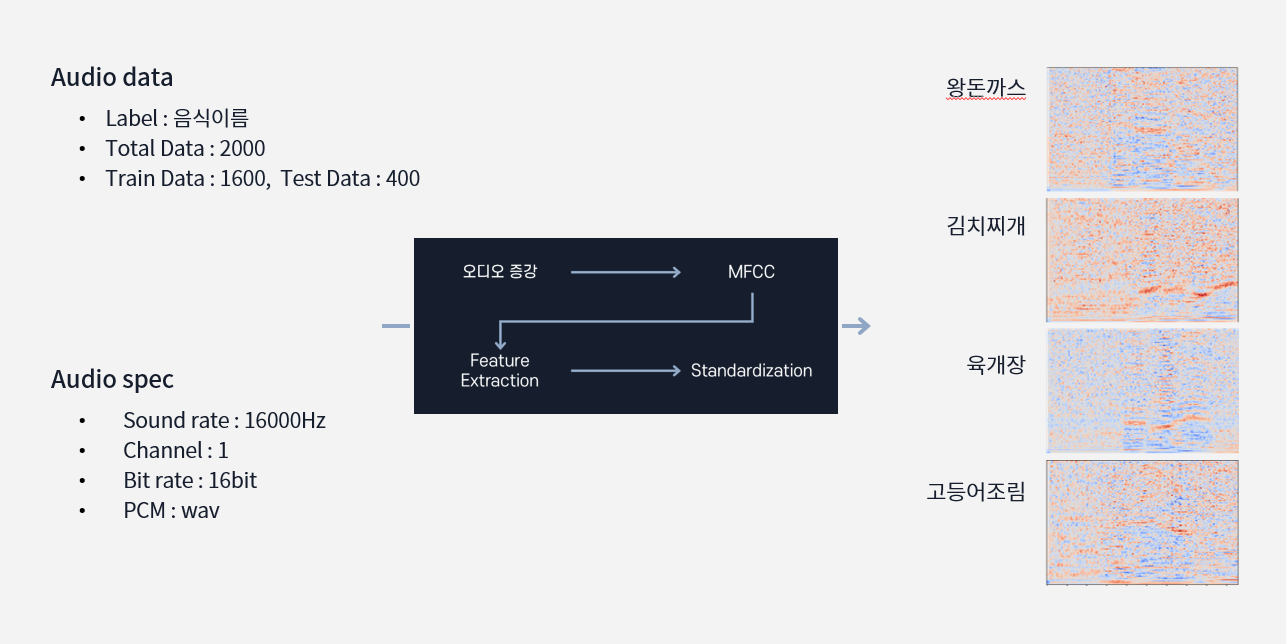
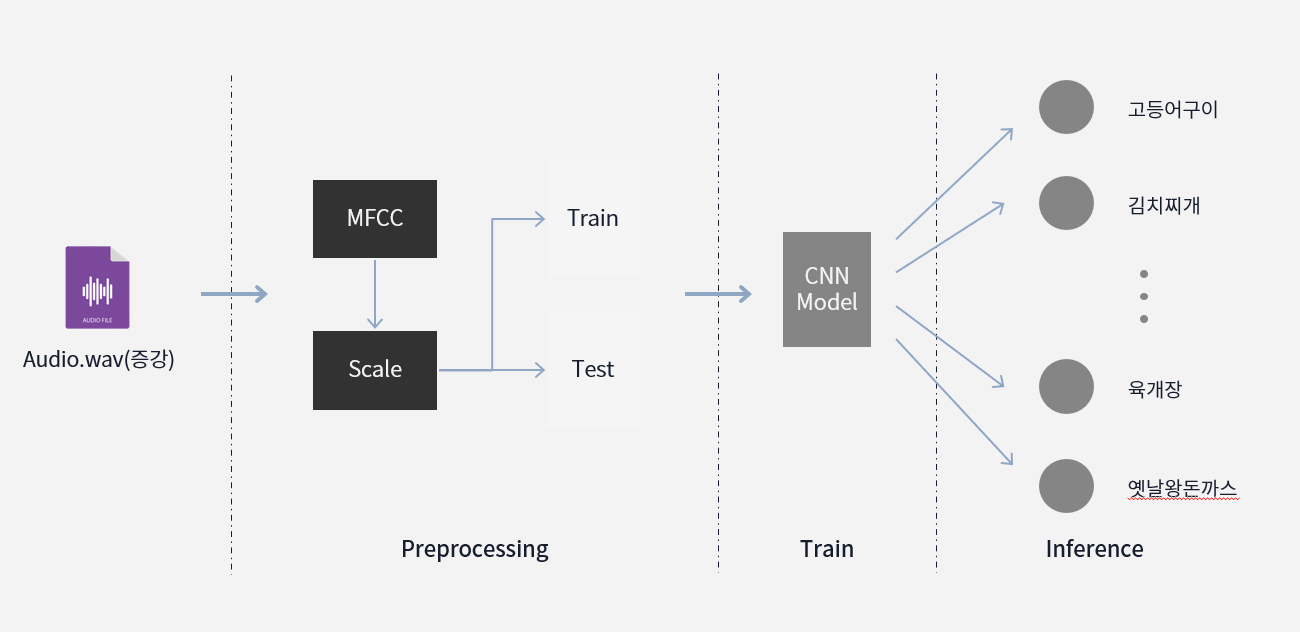
OpenAPI를 사용해서 구현하는 것은 크게 도움이 되지 않는다고 판단을 하고 Librosa의 MFCC로 오디오 피처 추출을 하고 이미지화 시켜서 CNN으로 학습시키는 방향으로 진행하게 되었다.
이 방식은 전체 음성을 판단하는 것이 아닌 단어로만 예측할 수 있게 STT를 구현해 본 것이다.
□ 아쉬운 점
이미지 input - image inference 사이에 걸리는 시간이 약 7~8초 소요되어 시간을 줄이려는 작업을 진행하였지만 많이 줄이진 못하였다.
배포된 추론 모델에서 걸리는 시간 약 1.7 ~ 2.3초가 걸린다. 추론 모델에서 시간을 줄일 수 없고, 다른 부분에서 시간을 줄여야 했고, 시간을 지연시키는 문제를 찾아보았다.
시간을 지연시키는 문제
1. Goofys를 이용하여 s3 - ec2 마운트한 폴더가 생각보다 실시간이 아닌 어느정도 딜레이가 존재
2. s3에 이미지 input시 lambda가 작동하는데 발생하는 시간
위처럼 2가지가 존재하였고 1번 문제는 해결하지 못하였고, 2번 문제에서 lambda의 메모리가 default로 128로 되어있는데 이것을 1024로 올리면 5초 -> 3초로 줄어들었지만, 그만큼 Lambda를 작동하는 비용이 상승하게 되어 속도를 얻고 비용적으로 손해를 보게 되었다.
□ 어려웠던 점과 해결 방법
Linux shell script 작성과 AWS 서비스는 처음 해보는 것이라서 많은 시행착오가 발생했었다.
쉘스크립트는 생각보다 이해하기 어렵지 않아 구현하는 것에 있어 크게 문제가 없었지만, AWS에서 각 서비스의 정책 설정이나 Lambda 코드를 작성하는 것에 상대적으로 많은 시간을 투자해야했다.
또한 내가 구상한 아키텍쳐에 대한 한글 Referece가 적었으며, 심지어 원문으로 검색하여도 원하는 방식은 없어서 각 서비스를 완벽하게 이해하고 직접 적용하는 방법 밖에 없어 구현하는 것이 쉽지 않았지만, 구글선생님과 어려워도 포기하지 않고 시도해보니 최종적으로는 구현을 해내게 되었다.
□ 배운점 및 느낀점
이번 프로젝트를 하면서 리눅스를 왜 사용하는 것이 좋은지에 대한 부분을 조금 느낄 수 있었고, AWS는 정말 정해진 것이 없고 원하는 방식대로 구성할 수 있다는 것에 AWS 서비스의 대단함을 느꼈다.
그리고 막상 AWS를 이용하여 자동화를 구현한 것을 살펴보면 크게 한 것도 없어보인다. 그만큼 이해하는데 많은 시간을 사용하였고, 멀리서 보니 자동화가 허술해 보이는 것이 여러 포인트가 보인다.
자동화를 구현화 해보면서 정말 알아야 할 것이 많고 아는 것도 없는 것을 느끼게 되어 자신감도 많이 잃었지만, 그래도 어떻게든 구현했다는 점에서 스스로를 칭찬해주고 싶다.
□ 프로젝트 ppt
Google Slides 로드 중
Google Slides에서 "no_name project.pptx" 파일을 엽니다. 몇 분 정도 소요될 수 있습니다.
docs.google.com
□ GITHUB
GitHub - kch8906/Final_Project
Contribute to kch8906/Final_Project development by creating an account on GitHub.
github.com
□ 시연영상
'Project' 카테고리의 다른 글
| [AI]운전자 졸음 탐지와 졸음 환경 감지 서비스 (0) | 2022.07.02 |
|---|