지난 빅데이터 공모전에서 받은 데이터 셋으로 XGBoost로 추천시스템을 구현해보고 이것을 kubeflow로 파이프라인을 구축 하는 중이다. 맨땅에서 시도하다보니 너무 많은 이슈가 발생해서 정신이 없지만 확실히 에러한테 맞아가면서 익히는게 학습이 빠른거 같다.
kubeflow로 s3에서 데이터를 불러오는 것부터 배포하는 것까지 pipeline 노드 별로 작성해 보려 한다.
이번 포스트는 AWS S3 버킷에서 csv를 받아와서 csv를 json으로 변환하는 노드이다.
GitHub - kch8906/kubeflow-xgboost-recommendation
Contribute to kch8906/kubeflow-xgboost-recommendation development by creating an account on GitHub.
github.com
Prerequisite
- Kubernetes : v1.19.3
- Kustomize : v3.2.0
- Kubeflow : v1.4.0
1. DATASET
빅데이터 공모전에서 받은 데이터 총 6개 중 3개만 사용하였고 CSV파일로 구성되어 있다.
이 데이터를 AWS S3 스토리지에 올려서 관리한다고 생각하고 S3에서 진행했다.
2. Convert Json
S3에서 CSV땡겨오는 Download.py와 다운로드 이후에 Preprocess.py로 넘어가는 Pipeline을 구성하였었는데
CSV가 다음 컨테이너로 파이프라인을 타고 넘어가는 과정에서 에러가 발생했다. 넘어와서 처리된 CSV를 열어봤는데 아무것도 없어서 CSV가 넘어올 때 형식 정확하게는 모르지만 형식이 존재하는 것 같아 Json으로 변환 후 넘겨보았더니 잘 되었다.
convertJson.py
import boto3
import json
import pandas as pd
def s3_download():
s3_client = boto3.client('s3', region_name='ap-northeast-2',
aws_access_key_id='[your_access_key]',
aws_secret_access_key='[your_secret_access_key]')
bucket = 'changhyun-xgboost'
filenames = ['LPOINT_BIG_COMP_01_DEMO.csv', 'LPOINT_BIG_COMP_02_PDDE.csv', 'LPOINT_BIG_COMP_04_PD_CLAC.csv']
object_name = ['df_customer.csv', 'df_purchase.csv', 'df_product.csv']
for i in range(len(filenames)):
s3_client.download_file(bucket, filenames[i], object_name[i])
def convert_json(df: pd.DataFrame, jsonname: str):
df.to_json(f"{jsonname}.json", orient = "records")
if __name__ == "__main__":
print("Downloading data..")
s3_download()
print("Download Success")
data_file_path = '/tmp/'
csvNames = ['df_customer', 'df_purchase', 'df_product']
for csvName in csvNames:
path = ''.join(data_file_path + csvName + '.csv')
df = pd.read_csv(path, low_memory=False)
convert_json(df, csvName)본래 s3 접속은 저런식으로 하면 안된다...
aws-secret을 이용해서 apply로 use_aws_secret을 이용해야 하는데 aws-secret.yaml을 만들어서 적용시켜주었는데도 인식을 못하였다. 이건 추후에 알아봐야 할 듯 싶다.
위 코드는 s3에서 csv로 받아서 json으로 변형하여 df라는 객체로 컨테이너 내부에 저장한다.
3. Docker
각 노드들을 도커로 컨테이너화하여 사용했기 때문에 이번 페이지에만 작성해보려 한다.
모든 노드는 아니지만 대부분 노드들이 살짝 바꾸는 형식으로 적용 될 수 있기 때문에 한번 이해해두면 안봐도 사용 할 수 있을 것이다.
처음 노드인 convertJson의 구성 파일은 [convertJson.py, Dockerfile, requirements.txt]로 구성되어있다.
상단의 코드가 convertJson.py이고 requirements.txt 내부에는 도커 컨테이너 내부에 설치할 pandas, boto3만 존재한다
Dockerfile
FROM python:3.8-slim
WORKDIR /tmp
RUN apt-get update
COPY requirements.txt ./requirements.txt
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
COPY convertJson.py ./convertJson.py
ENTRYPOINT [ "python", "convertJson.py" ]
3-1 Docker Build
터미널에서 Dockerfile이 존재하는 곳으로 이동
docker build -t crysiss/kubeflow-convert:0.1 .crysiss/kubeflow-convert:0.1은 원하는 명칭으로 하면되며 앞의 crysiss는 Docker hub의 아이디를 쓰면 된다.
:0.1은 tag 넘버이고 맨 마지막에 . 찍는걸 잊지 말자
3-2 Docker push
docker push crysiss/kubeflow-convert:0.1도커 빌드를 했다면 image가 생성되었을 것이고 생성 되었다면 docker hub에 push를 해야한다 (github 개념이랑 비슷하다)
3-3 Docker hub
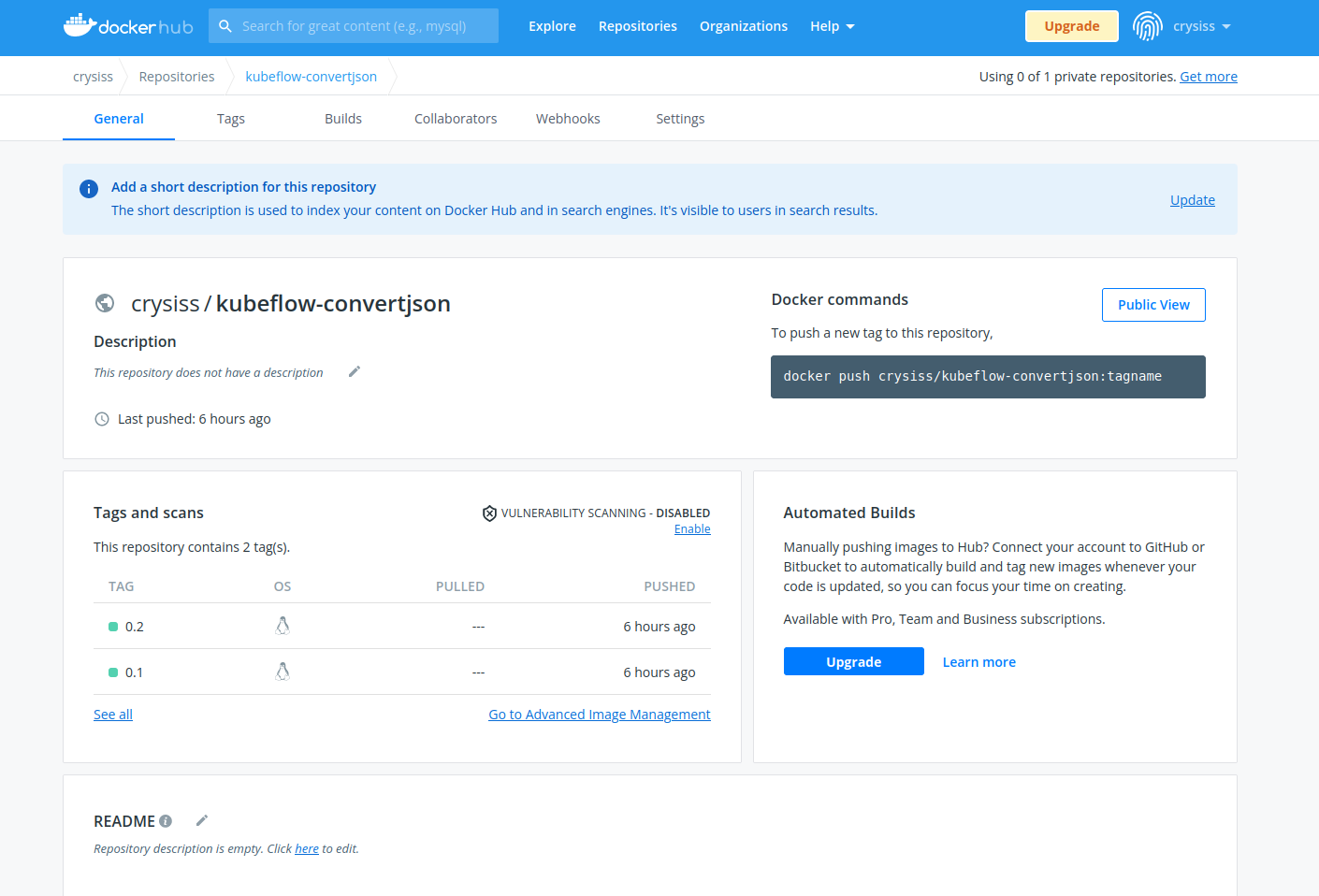
tag 넘버를 0.1로 push를 하면 docker hub 레파지토리 내부에 0.1이 존재하면 push가 된 것이다.
4. kfp
kubeflow pipeline을 구성하는 코드를 따로 작성해야한다.
pipeline.py
import kfp
from kfp import dsl
def convert_json():
return dsl.ContainerOp(
name='Convert Data',
image='crysiss/kubeflow-convertjson:0.2',
arguments=[],
file_outputs={
'df_customer': '/tmp/df_customer.json',
'df_purchase': '/tmp/df_purchase.json',
'df_product': '/tmp/df_product.json'
}
)
@dsl.pipeline(name='XGBOOST-REC Pipeline',
description='A pipeline that trains and logs a classification model'
)
def data_pipeline():
_convert_json = convert_json()
if __name__ == "__main__":
import kfp.compiler as compiler
compiler.Compiler().compile(data_pipeline, 'pipeline.tar.gz')
kfp 라이브러리의 dsl.ContainerOp() 함수를 이용해서 도커 컨테이너 이미지를 불러온다.
- image는 도커 레파지토리에 업로드 되어있는 [이름:태그] 형식
- arguments는 해당 노드에서 사용하게 될 데이터
- file_outputs은 해당 노드에서 생성된 파일을 output으로 지정하는 것, 다음 파이프라인을 통해 보낼 파일을 명시해주면 된다

생성된 pipeline.tar.gz 파일을 kubeflow pipeline에 등록해주고 실행시켜서 위 사진중 첫번째의 컴포넌트가 초록색으로 활성화 되면 성공이다.
'MLOps' 카테고리의 다른 글
| k8s v1.25.2 master node 구축 (0) | 2022.10.11 |
|---|---|
| [kubeflow] Recommandation(XGBoost) 파이프라인 구축 - 2 (0) | 2022.09.26 |
| [Docker] 설치 및 기본 명령어 (0) | 2022.09.01 |